
Embark on an exciting journey through Quiz 9.1 A AP Statistics, where we’ll dive into the captivating world of sampling, hypothesis testing, and statistical inference. Get ready to unravel the secrets of data analysis and gain a deeper understanding of how to make informed decisions based on statistical evidence.
From exploring the fundamentals of sampling to delving into the intricacies of confidence intervals and hypothesis testing, this quiz will challenge your critical thinking skills and equip you with essential statistical knowledge. So, buckle up and let’s embark on this statistical adventure together!
Chapter 9.1 Concepts

In statistical inference, sampling plays a crucial role. It allows researchers to make generalizations about a population based on data collected from a smaller subset, known as a sample. Sampling provides valuable insights into the characteristics of a population, enabling researchers to draw conclusions without having to examine every single member.
There are various types of sampling methods, each with its own advantages and disadvantages. Some common methods include:
- Simple random sampling:Each member of the population has an equal chance of being selected.
- Systematic sampling:Members are selected at regular intervals from a list or database.
- Stratified sampling:The population is divided into subgroups (strata), and members are randomly selected from each stratum.
- Cluster sampling:The population is divided into clusters, and a random sample of clusters is selected.
Randomization is an essential aspect of sampling. It helps to reduce bias and ensure that the sample is representative of the population. By randomly selecting members, researchers can avoid systematic errors that could lead to inaccurate conclusions.
Sampling Distributions
In statistics, a sampling distribution refers to the probability distribution of a statistic (such as the sample mean or proportion) that is calculated from repeated random samples of a given size from a population.
Quiz 9.1 A AP Statistics can be a bit of a challenge, but don’t worry! Check out fiveable ap world unit 8 for some helpful resources. With their in-depth explanations and practice questions, you’ll be well-prepared to ace that quiz! Once you’ve brushed up on your knowledge, come back and tackle Quiz 9.1 A AP Statistics with confidence.
The sampling distribution provides insights into the behavior of the statistic as the sample size increases. It helps us understand the variability and accuracy of the statistic as an estimate of the population parameter.
Properties of Sampling Distributions
Sampling distributions have several key properties:
- Central Limit Theorem:As the sample size increases, the sampling distribution of the sample mean approaches a normal distribution, regardless of the shape of the population distribution.
- Mean:The mean of the sampling distribution is equal to the mean of the population.
- Standard Deviation:The standard deviation of the sampling distribution, known as the standard error, is inversely proportional to the square root of the sample size.
Central Limit Theorem
The Central Limit Theorem is a fundamental theorem in statistics that states that the distribution of sample means approaches a normal distribution as the sample size increases, regardless of the shape of the population distribution.
This theorem has significant implications for sampling distributions. It allows us to make inferences about the population mean based on the sample mean, even when the population distribution is unknown.
Confidence Intervals
A confidence interval is a range of values that is likely to contain the true population mean. It is constructed based on a sample of data and is used to estimate the population mean with a certain level of confidence.
To construct a confidence interval for a population mean, we follow these steps:
- Calculate the sample mean and sample standard deviation.
- Find the critical value from the t-distribution or z-distribution, depending on the sample size and the desired confidence level.
- Multiply the critical value by the standard error of the mean to get the margin of error.
- Add and subtract the margin of error from the sample mean to get the lower and upper bounds of the confidence interval.
The width of a confidence interval is affected by several factors, including the sample size, the standard deviation of the population, and the desired confidence level. A larger sample size and a smaller standard deviation will result in a narrower confidence interval, while a higher confidence level will result in a wider confidence interval.
Hypothesis Testing
Hypothesis testing is a statistical method used to determine whether a particular claim about a population is supported by the available evidence. It involves comparing a sample statistic to a hypothesized population parameter to assess whether the sample provides enough evidence to reject the hypothesis.
The steps involved in hypothesis testing are as follows:
- State the null and alternative hypotheses.
- Set the significance level.
- Calculate the test statistic.
- Determine the p-value.
- Make a decision.
Types of Errors
There are two types of errors that can occur in hypothesis testing:
- Type I error: Rejecting the null hypothesis when it is true (false positive).
- Type II error: Failing to reject the null hypothesis when it is false (false negative).
One-Sample Tests
The one-sample t-test is a statistical test used to determine if the mean of a population is equal to a specified value. It is a type of hypothesis test that assumes the population is normally distributed and has a known standard deviation.The
one-sample t-test can be used to test a variety of hypotheses, including:* Whether the mean of a population is equal to a specific value
- Whether the mean of a population is greater than or less than a specific value
- Whether the mean of a population is different from a specific value
Power of the One-Sample t-Test, Quiz 9.1 a ap statistics
The power of a statistical test is the probability of rejecting the null hypothesis when it is false. The power of the one-sample t-test is affected by several factors, including:* The sample size
- The standard deviation of the population
- The effect size
The larger the sample size, the greater the power of the test. The smaller the standard deviation of the population, the greater the power of the test. The larger the effect size, the greater the power of the test.
Two-Sample Tests
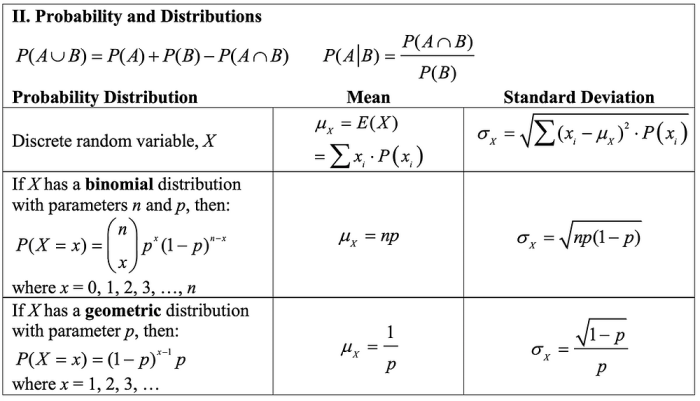
Two-sample tests are used to compare the means of two independent populations. The two-sample t-test is a statistical test that can be used to determine if there is a significant difference between the means of two independent populations.
Assumptions of the Two-Sample t-Test
The two-sample t-test assumes that the two populations are independent, normally distributed, and have equal variances.
Examples of How the Two-Sample t-Test Can Be Used
The two-sample t-test can be used to compare the means of two independent populations in a variety of settings. For example, the two-sample t-test can be used to compare the mean weight of two different breeds of dogs, the mean height of two different groups of students, or the mean income of two different groups of workers.
Power of the Two-Sample t-Test
The power of a statistical test is the probability of rejecting the null hypothesis when it is false. The power of the two-sample t-test depends on the following factors:
- The size of the difference between the means of the two populations
- The sample size
- The variance of the two populations
Correlation and Regression: Quiz 9.1 A Ap Statistics
In statistics, correlation and regression are two closely related concepts that help us understand the relationship between two or more variables. Correlation measures the strength and direction of the linear relationship between two variables, while regression allows us to predict the value of one variable based on the value of another.
Correlation
Correlation is a statistical measure that quantifies the extent to which two variables are linearly related. It ranges from -1 to 1, where:
- A correlation of 1 indicates a perfect positive linear relationship, meaning that as one variable increases, the other variable also increases.
- A correlation of -1 indicates a perfect negative linear relationship, meaning that as one variable increases, the other variable decreases.
- A correlation of 0 indicates no linear relationship between the two variables.
There are different types of correlation coefficients, each measuring a different aspect of the relationship between two variables:
- Pearson correlation coefficient: Measures the linear relationship between two continuous variables.
- Spearman correlation coefficient: Measures the monotonic relationship between two ordinal variables.
- Kendall correlation coefficient: Measures the concordance between two ordinal variables.
Regression
Regression is a statistical technique that allows us to predict the value of one variable (the dependent variable) based on the value of another variable (the independent variable). The relationship between the two variables is represented by a regression line, which is a straight line that best fits the data points.
The regression line is defined by the following equation:
y = a + bx
where:
- y is the dependent variable
- x is the independent variable
- a is the y-intercept (the value of y when x = 0)
- b is the slope (the change in y for a one-unit change in x)
Regression analysis is a powerful tool for understanding the relationship between two or more variables and making predictions.
Chi-Square Tests
The chi-square test is a statistical test used to determine whether there is a significant difference between the expected frequencies and the observed frequencies of events in one or more categories. It is a non-parametric test, which means that it does not require the data to be normally distributed.
The chi-square test is based on the chi-square distribution, which is a probability distribution that describes the distribution of the sum of the squares of independent standard normal random variables. The chi-square distribution is a right-skewed distribution with a mean of df and a variance of 2df, where df is the degrees of freedom.
Assumptions of the Chi-Square Test
- The data must be categorical.
- The expected frequencies must be at least 5 for each category.
- The observations must be independent.
Examples of How the Chi-Square Test Can Be Used
- To test whether the distribution of a population is different from a specified distribution.
- To test whether two or more populations have the same distribution.
- To test whether a treatment has an effect on a population.
Power of the Chi-Square Test
The power of a statistical test is the probability of rejecting the null hypothesis when it is false. The power of the chi-square test depends on the following factors:
- The sample size
- The number of categories
- The effect size
Key Questions Answered
What is the importance of sampling in statistical inference?
Sampling allows us to make inferences about a large population by studying a smaller, representative sample, saving time and resources.
What is the Central Limit Theorem and its significance?
The Central Limit Theorem states that as sample size increases, the sampling distribution of sample means approaches a normal distribution, regardless of the shape of the population distribution. This is crucial for constructing confidence intervals and conducting hypothesis tests.
What are the different types of hypothesis testing errors?
There are two types of errors in hypothesis testing: Type I error (rejecting a true null hypothesis) and Type II error (failing to reject a false null hypothesis). Minimizing these errors is essential for accurate statistical conclusions.
